


Ahmed Nouman
Saurav Khadka

What if a single AI system could draft a legal memo, interpret a medical scan, and guide a robot arm — all before lunch? Foundation models are making this a reality, marking a fundamental shift from narrow, task-specific AI to large, broadly capable systems that adapt to almost any challenge with just a few written instructions. Once confined to research labs, these models now power the AI tools millions of people use every day and understanding how they work is becoming as essential as digital literacy itself.
Think about an intelligent system capable of writing a legal memo in the morning, explaining what is in an X-ray in the afternoon, and a robotic arm to sort recycled material in the evening. These tasks are complex because they require different forms of intelligence. One requires understanding language, another requires interpreting images, and the third requires connecting intelligence to physical action. Just a few years ago, each of them needed a specific model that was trained on its own hand-crafted dataset in simple terms, a model can be understood as a system that receives input, processes them, and produces outputs.
Foundation models are changing this earlier approach of training task-specific models. Often, one large model can perform all the tasks discussed above, and many more, with just a few written instructions. This article discusses the nature of foundation models, their position within the overall framework of the field of artificial intelligence, the primary modalities that foundation models represent, and why they have elicited such an impressive amount of interest among researchers, industries, and society.
What Are Foundation Models?
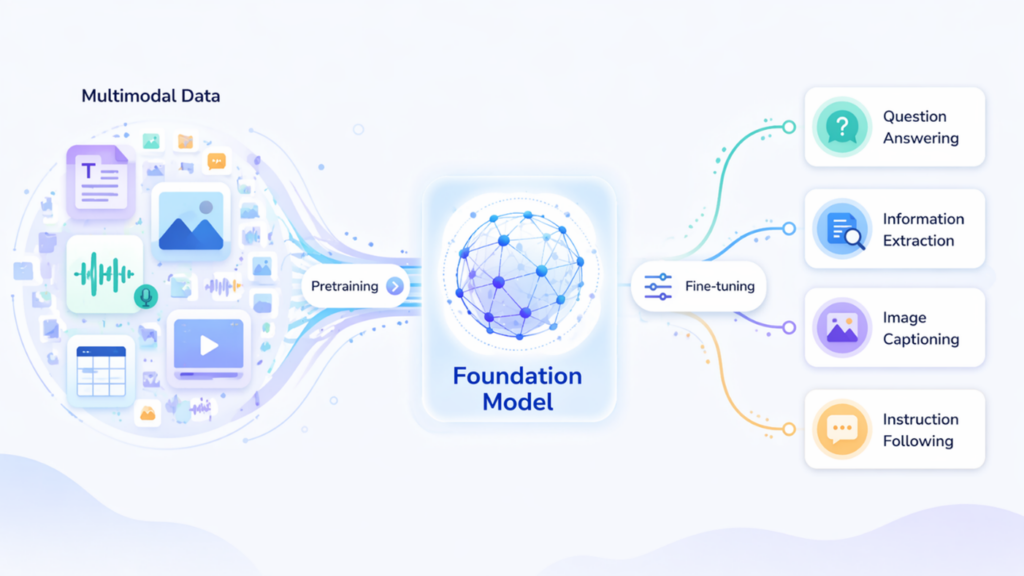
In 2021, researchers at Stanford University coined the term foundation model to describe a new category of general-purpose model, which is defined to be trained on large-scale generic data and able to be fine-tuned to a vast variety of downstream tasks (Bommasani et al. 2021). It is not a particular architecture but rather a practice: a large model, pre-trained on vast amounts of mostly unlabeled data, is the basis upon which numerous specialized tasks can be performed through relatively small modifications – fine-tuning, prompting, or just rephrasing a query. Figure 1 illustrates how foundation models are pretrained on large-scale multimodal data and then adapted for a range of downstream tasks.
Conventional machine learning would use a single model to categorize emails as spam and a different model to translate text between languages. Contrastingly, a foundation model is trained on general patterns of language, vision, or sensor data, then during pre-training, can be repurposed to spam detection, translation, summarization, or image captioning without being re-trained. It is this change, that is, the multiplicity of task-specific models into a small number of broadly able models, which makes the paradigm worth a special name.
Where Foundation Models Fit in the AI Landscape
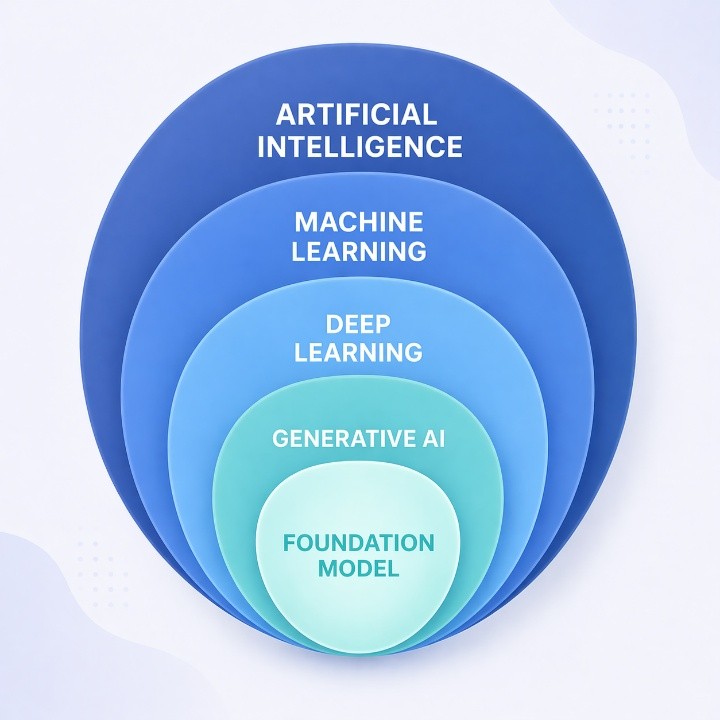
Artificial intelligence is the overarching field that deals with the creation of systems that possess human intelligence in nature. It contains the subfield of machine learning where systems acquire patterns by learning data instead of by hand-written rules, and deep learning is the subfield of machine learning based on artificial neural networks with many layers (LeCun, Bengio & Hinton 2015). The most advanced models in deep learning are foundation models: these are extremely large neural networks, typically built around the transformer architecture (Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser & Polosukhin 2017), trained on very large datasets, and intended to be used as a universal base by lots of applications. Figure 2 visualizes the relationship between artificial intelligence, machine learning, deep learning, generative AI, and foundation models. In brief, foundation models represent a particular form of deep learning – characterized by their size, their generality of the training data they are trained on, and their flexibility to tasks which the creators of these models had not explicitly in mind.
Brief History and Rise to Mainstream
The components of foundation models were built over time. The transformer architecture (Vaswani et al. 2017) made it possible to train in extremely long text sequences. BERT (Devlin, Chang, Lee & Toutanova 2018) demonstrated that with just a single pre-trained language model, it was possible to fine-tune it to be at par or even surpassing task-specific systems in most benchmarks. GPT-3 (Brown et al. 2020) showed that a further scaled up version of these models provided a qualitatively different capability: the capability to perform new tasks, given a small number of examples in the prompt, without further training. The ChatGPT technology was then publicly introduced in November 2022, and models like GPT-4 (OpenAI et al. 2023), the Llama family (Touvron et al. 2023), and Google’s Gemini (Anil et al. 2023) expanded the paradigm to images, audio, and structured reasoning. What just a couple of years prior was a scholarly research focus became, in a few years, the mainstream infrastructure.
Modalities of Foundation Models
Early foundation models worked only with text, but the paradigm has since expanded across many modal forms of data. The most prominent categories are described below.
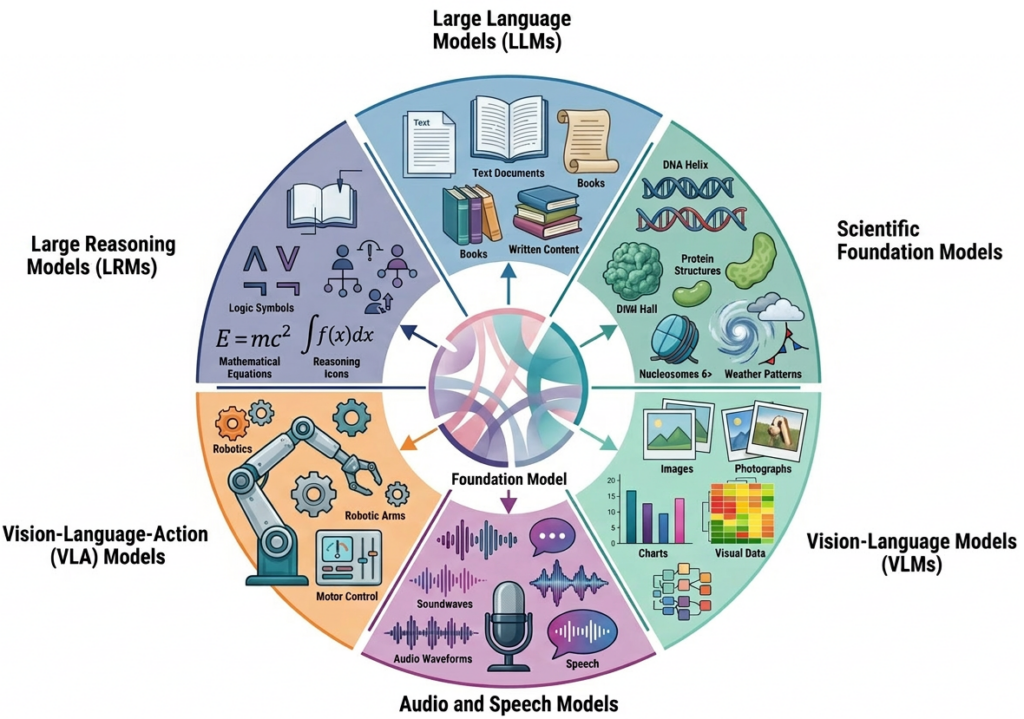
Large Language Models (LLMs)
Large Language Models are text-based foundation models. They are taught to guess the following token – a word fragment – based on the context preceding the token, and on this basic task develop an impressive repertoire of skills: question answering, document summarizing, cross-linguistic translation, email writing, and software writing. The most notable ones are the GPT family (Brown et al. 2020; OpenAI et al. 2023), the open-weight Llama models (Touvron et al. 2023), Claude of Anthropic (Anthropic 2024), and Gemini by Google (Anil et al. 2023). Most consumer AI assistants now rely on LLM as their backbone, and it is the most noticeable aspect of the foundation-model revolution.
Large Reasoning Models (LRMs)
A more recent form is the Large Reasoning Model, which is trained to devote extra computation to generating an internal chain of thought before providing its final answer. The strategy is based on encouraging an LLM to think step-by-step and leads to its better performance in mathematics, logic, and code (Wei, Wang, Schuurmans, Bosma, Ichter, Xia, Chi, Le & Zhou 2022). Some models like the o1 and o3 series of OpenAI or the modes of extended thought of Claude and Gemini extend this concept by learning reasoning as a skill. LRMs are slower and more costly per query than typical LLMs, but far more accurate on issues that involve a sequence of inferences to be made.
Vision Language Models (VLMs)
Vision Language Models are systems that use a combination of images and text. One of the initial notable cases was CLIP (Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger & Sutskever 2021) that was trained to match images with their textual description using a dataset of several hundred million image-text pairs sampled on the web. Newer VLMs like GPT-4V, Claude, and Gemini can describe what is in a photograph, read charts and diagrams, and find information in scanned documents, as well as respond to questions about medical pictures. Simultaneously, vision-only foundation models like the Segment Anything Model (Kirillov, Mintun, Ravi, Mao, Rolland, Gustafson, Xiao, Whitehead, Berg, Lo, Dollár & Girshick 2023) have demonstrated that the same paradigm, a single large model, trained on large and diverse data, applied to a wide range of downstream tasks, transfers to pure computer vision.
Audio and Speech Foundation Models
Foundation models are now standard for audio as well. The Whisper (Radford, Kim, Xu, Brockman, McLeavey & Sutskever 2022) speech-recognition model of OpenAI is trained on almost seven hundred thousand hours of multi-language audio; it can transcribe, translate, and detect the language of spoken speech in almost a hundred different languages without task-specific fine-tuning. Similar models produce natural speech, isolate musical instruments in a mixed recording, or identify machine malfunctions based on acoustic features.
Vision-Language-Action Models (VLAs)
The latest frontier is the Vision-Language-Action model that introduces the foundation model paradigm to robotics. A VLA receives pictures of what a robot camera sees and a natural-language command like “pick up the red block and put it on the plate” and just writes the motor instructions required to accomplish the task. Google DeepMind RT-2 (Brohan et al. 2023) demonstrated that a VLM fine-tuned on data regarding the robot could transfer the knowledge about the internet to physical manipulation – it recognized objects it had never seen during robot training because it had seen them in web images. VLAs are not yet fully developed but are a possible path to general-purpose robots.
Scientific and Domain-Specific Foundation Models
The applications of foundation model have been extended to areas way outside language. AlphaFold 2 (Jumper et al. 2021) predicts protein structural 3D folding based on amino-acid sequences, and is already transforming computational biology, with accuracy comparable to experimental techniques. Weather forecasting, materials discovery, medical imaging, and chemistry are some of the similar models being trained on large curated scientific datasets, as opposed to text on the internet.
Applications, Hype, and Real Potential
The excitement of foundation models has been associated with real successes as well as a sort of hype, and it is worth distinguishing between the two. Already being applied on the achievement side, foundation models are used in production to develop software (code completion and review), provide customer support (chatbots and routing systems), healthcare (summarizing clinical notes and assisting with medical imaging), education (personalized tutoring), scientific research (literature review and hypothesis generation), and creative work (writing, image generation, music, and video). Productivity improvements and capabilities have been reported in all these areas.
Simultaneously, the technology is genuinely limited. The foundation models may generate confident but false statements – so-called hallucinations – and their arguments may fail in unpredictable ways. They pass over to them biases in their training data, give rise to novel questions about copyright and privacy, use a large amount of energy in their training and deployment, and put capability in the control of the comparatively few organizations that can afford to train them. The Stanford foundation model report (Bommasani et al. 2021) clearly framed its analysis in terms of opportunities and risks, and that is the correct framing.
Looking forward, the most credible near-term potential lies in foundation models as a general-purpose productivity layer – a flexible tool that individuals and organizations use to offload routine cognitive and perceptual work, combined with specialized systems where reliability matters most. In robotics, VLAs may eventually deliver robots that can be instructed in plain language rather than programmed. In science, domain-specific foundation models may accelerate discovery in fields where data is plentiful, but theory is thin. Whether these possibilities mature into sustained impact will depend not only on further technical progress but on how carefully the surrounding questions of safety, evaluation, and governance are addressed.
Conclusion
Foundation models represent a genuine shift in how artificial intelligence is built: from many narrow systems, each trained for a single purpose, to a smaller number of large, broadly capable models that are adapted to many tasks. Their modalities – language, reasoning, vision, audio, action, and scientific data – are converging into systems that can perceive, reason, and act in increasingly integrated ways. For researchers, engineers, and institutions in the world, foundation models are now both a subject worth understanding and a practical tool worth learning to use responsibly.
References
Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., Silver, D., Johnson, M., Antonoglou, I., Schrittwieser, J., Glaese, A., Chen, J., Pitler, E., Lillicrap, T., Lazaridou, A., Firat, O., Molloy, J., Isard, M., Barham, P. R., Hennigan, T., Lee, B., Viola, F., Reynolds, M., Xu, Y., Doherty, R., Collins, E., Meyer, C., Rutherford, E., Moreira, E., Ayoub, K., Goel, M., Krawczyk, J., Du, C., Chi, E., Cheng, H.-T., Ni, E., Shah, P., Kane, P., Chan, B., Faruqui, M., Severyn, A., Lin, H., Li, Y., Cheng, Y., Ittycheriah, A., Mahdieh, M., Chen, M., Sun, P., Tran, D., Bagri, S., Lakshminarayanan, B., Liu, J., Orban, A., Güra, F., Zhou, H., Song, X., Boffy, A., Ganapathy, H., Zheng, S., Choe, H., Weisz, Á., Zhu, T., Lu, Y., Gopal, S., Kahn, J., Kula, M., Pitman, J., Shah, R., Taropa, E., Al Merey, M., Baeuml, M., Chen, Z., El Shafey, L., Zhang, Y., Sercinoglu, O., Tucker, G., Piqueras, E., Krikun, M., Barr, I., Savinov, N., Danihelka, I., Roelofs, B., White, A., Andreassen, A., von Glehn, T., Yagati, L., Kazemi, M., Gonzalez, L., Khalman, M., Sygnowski, J., Frechette, A., Smith, C., Culp, L., Proleev, L., Luan, Y., Chen, X. et al. 2023. Gemini: A Family of Highly Capable Multimodal Models. ArXiv:2312.11805. Available at: https://doi.org/10.48550/ARXIV.2312.11805. Accessed 17 April 2026.
Anthropic. 2024. The Claude Model Family: Opus, Sonnet, Haiku. Model Card. Available at: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf. Accessed 17 April 2026.
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J. Q., Demszky, D., Donahue, C., Doumbouya, M., Durmus, E., Ermon, S., Etchemendy, J., Ethayarajh, K., Fei-Fei, L., Finn, C., Gale, T., Gillespie, L., Goel, K., Goodman, N., Grossman, S., Guha, N., Hashimoto, T., Henderson, P., Hewitt, J., Ho, D. E., Hong, J., Hsu, K., Huang, J., Icard, T., Jain, S., Jurafsky, D., Kalluri, P., Karamcheti, S., Keeling, G., Khani, F., Khattab, O., Koh, P. W., Krass, M., Krishna, R., Kuditipudi, R., Kumar, A., Ladhak, F., Lee, M., Lee, T., Leskovec, J., Levent, I., Li, X. L., Li, X., Ma, T., Malik, A., Manning, C. D., Mirchandani, S., Mitchell, E., Munyikwa, Z., Nair, S., Narayan, A., Narayanan, D., Newman, B., Nie, A., Niebles, J. C., Nilforoshan, H., Nyarko, J., Ogut, G., Orr, L., Papadimitriou, I., Park, J. S., Piech, C., Portelance, E., Potts, C., Raghunathan, A., Reich, R., Ren, H., Rong, F., Roohani, Y., Ruiz, C., Ryan, J., Ré, C., Sadigh, D., Sagawa, S., Santhanam, K., Shih, A., Srinivasan, K., Tamkin, A., Taori, R., Thomas, A. W., Tramèr, F., Wang, R. E., Wang, W. et al. 2021. On the Opportunities and Risks of Foundation Models. arXiv:2108.07258. Available at: https://doi.org/10.48550/ARXIV.2108.07258. Accessed 17 April 2026.
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P., Fu, C., Gonzalez Arenas, M., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.-W. E., Levine, S., Lu, Y., Michalewski, H., Mordatch, I., Pertsch, K., Rao, K., Reymann, K., Ryoo, M., Salazar, G., Sanketi, P., Sermanet, P., Singh, J., Singh, A., Soricut, R., Tran, H., Vanhoucke, V., Vuong, Q., Wahid, A., Welker, S., Wohlhart, P., Wu, J., Xia, F., Xiao, T., Xu, P., Xu, S., Yu, T. & Zitkovich, B. 2023. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv:2307.15818. Available at: https://doi.org/10.48550/ARXIV.2307.15818. Accessed 17 April 2026.
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I. & Amodei, D. 2020. Language Models are Few-Shot Learners. arXiv:2005.14165. Available at: https://doi.org/10.48550/ARXIV.2005.14165. Accessed 17 April 2026.
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805. Available at: https://doi.org/10.48550/ARXIV.1810.04805. Accessed 17 April 2026.
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., Tunyasuvunakool, K., Bates, R., Žídek, A., Potapenko, A., Bridgland, A., Meyer, C., Kohl, S. A. A., Ballard, A. J., Cowie, A., Romera-Paredes, B., Nikolov, S., Jain, R., Adler, J., Back, T., Petersen, S., Reiman, D., Clancy, E., Zielinski, M., Steinegger, M., Pacholska, M., Berghammer, T., Bodenstein, S., Silver, D., Vinyals, O., Senior, A. W., Kavukcuoglu, K., Kohli, P. & Hassabis, D. 2021. Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873), 583–589. Available at: https://doi.org/10.1038/s41586-021-03819-2. Accessed 17 April 2026.
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P. & Girshick, R. 2023. Segment Anything. arXiv:2304.02643. Available at: https://doi.org/10.48550/ARXIV.2304.02643. Accessed 17 April 2026.
LeCun, Y., Bengio, Y. & Hinton, G. 2015. Deep learning. Nature, 521(7553), 436–444. Available at: https://doi.org/10.1038/nature14539. Accessed 17 April 2026.
OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., Bello, I., Berdine, J., Bernadett-Shapiro, G., Berner, C., Bogdonoff, L., Boiko, O., Boyd, M., Brakman, A.-L., Brockman, G., Brooks, T., Brundage, M., Button, K., Cai, T., Campbell, R., Cann, A., Carey, B., Carlson, C., Carmichael, R., Chan, B., Chang, C., Chantzis, F., Chen, D., Chen, S., Chen, R., Chen, J., Chen, M., Chess, B., Cho, C., Chu, C., Chung, H. W., Cummings, D., Currier, J., Dai, Y., Decareaux, C., Degry, T., Deutsch, N., Deville, D., Dhar, A., Dohan, D., Dowling, S., Dunning, S., Ecoffet, A., Eleti, A., Eloundou, T., Farhi, D., Fedus, L., Felix, N., Fishman, S. P., Forte, J., Fulford, I., Gao, L., Georges, E., Gibson, C., Goel, V., Gogineni, T., Goh, G., Gontijo-Lopes, R., Gordon, J., Grafstein, M., Gray, S., Greene, R., Gross, J., Gu, S. S., Guo, Y., Hallacy, C., Han, J., Harris, J., He, Y., Heaton, M., Heidecke, J., Hesse, C., Hickey, A., Hickey, W., Hoeschele, P., Houghton, B., Hsu, K., Hu, S., Hu, X., Huizinga, J., Jain, S., Jain, S. 2023. GPT-4 Technical Report. arXiv:2303.08774. Available at: https://doi.org/10.48550/ARXIV.2303.08774. Accessed 17 April 2026.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G. & Sutskever, I. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020. Available at: https://doi.org/10.48550/ARXIV.2103.00020. Accessed 17 April 2026.
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C. & Sutskever, I. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356. Available at: https://doi.org/10.48550/ARXIV.2212.04356. Accessed 17 April 2026.
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P. S., Bhosale, S., Bikel, D., Blecher, L., Canton Ferrer, C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S. & Scialom, T. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288. Available at: https://doi.org/10.48550/ARXIV.2307.09288. Accessed 17 April 2026.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. & Polosukhin, I. 2017. Attention Is All You Need. arXiv:1706.03762. Available at: https://doi.org/10.48550/ARXIV.1706.03762. Accessed 17 April 2026.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q. & Zhou, D. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903. Available at: https://doi.org/10.48550/ARXIV.2201.11903. Accessed 17 April 2026.
Ahmed Nouman
RDI Expert
Centria University of Applied Sciences
p. 050 303 6086
Saurav Khadka
RDI Expert
Centria University of Applied Sciences
p. 050 595 2375